
LLM-Based Agents (大模型智能体)
 Large language models (LLMs) have demonstrated remarkable capabilities in language understanding, reasoning, and generation. Building upon these foundation models, LLM-based agents extend their capabilities by enabling them to perceive environments, reason over observations, and take actions autonomously. Our research investigates key challenges in this area, aiming to develop more capable, reliable, and efficient autonomous agents that can serve as general-purpose digital assistants across diverse real-world scenarios. >>Enter<<
Large language models (LLMs) have demonstrated remarkable capabilities in language understanding, reasoning, and generation. Building upon these foundation models, LLM-based agents extend their capabilities by enabling them to perceive environments, reason over observations, and take actions autonomously. Our research investigates key challenges in this area, aiming to develop more capable, reliable, and efficient autonomous agents that can serve as general-purpose digital assistants across diverse real-world scenarios. >>Enter<<
Open-World Machine Learning(开放世界下的机器学习)
 In many real-world applications, the insufficient labeled data, the emergence of novel classes, the different distributions of training and test data, and the imbalanced labels, usually degrade the performance of existing learning models. Thereby, we aim to propose new semi-supervised learning, novel class detection and learning, few-shot class-incremental learning, adversarial learning, transfer learning algorithms to handle many challenging problems in open real-world scenarios. >>Enter<<
In many real-world applications, the insufficient labeled data, the emergence of novel classes, the different distributions of training and test data, and the imbalanced labels, usually degrade the performance of existing learning models. Thereby, we aim to propose new semi-supervised learning, novel class detection and learning, few-shot class-incremental learning, adversarial learning, transfer learning algorithms to handle many challenging problems in open real-world scenarios. >>Enter<<
Graph Learning and Inference (图学习与推理)
 Graph learning focuses on developing robust representations of nodes and relationships in complex graph-structured data, enabling models to capture intrinsic structures and patterns effectively. Graph inference leverages these representations, often combined with large language models and knowledge graphs, to perform reasoning, answer complex queries, and derive new knowledge. Our research addresses key challenges in robustness, scalability, and knowledge-guided reasoning, aiming to empower intelligent systems with accurate and interpretable graph-based understanding. >>Enter<<
Graph learning focuses on developing robust representations of nodes and relationships in complex graph-structured data, enabling models to capture intrinsic structures and patterns effectively. Graph inference leverages these representations, often combined with large language models and knowledge graphs, to perform reasoning, answer complex queries, and derive new knowledge. Our research addresses key challenges in robustness, scalability, and knowledge-guided reasoning, aiming to empower intelligent systems with accurate and interpretable graph-based understanding. >>Enter<<
Distributed Data Stream Learning(分布式数据流学习)
 Data stream mining studies learning and decision-making from continuously arriving, potentially unbounded data streams under limited supervision and evolving distributions. Our research focuses on reliable semi-supervised learning in data streams, addressing challenges such as feature evolution, severe label imbalance, and the emergence of previously unseen classes. In addition, we explore federated learning over data streams to enable privacy-preserving and collaborative intelligence across distributed environments. These efforts aim to build adaptive, robust, and scalable learning systems capable of operating in dynamic real-world scenarios. >>Enter<<
Data stream mining studies learning and decision-making from continuously arriving, potentially unbounded data streams under limited supervision and evolving distributions. Our research focuses on reliable semi-supervised learning in data streams, addressing challenges such as feature evolution, severe label imbalance, and the emergence of previously unseen classes. In addition, we explore federated learning over data streams to enable privacy-preserving and collaborative intelligence across distributed environments. These efforts aim to build adaptive, robust, and scalable learning systems capable of operating in dynamic real-world scenarios. >>Enter<<
Multi-modal Data Fusion(多模态数据融合)
 Multi-modal data fusion aims to jointly model and integrate heterogeneous data from multiple modalities to enable comprehensive and reliable understanding of complex systems. Our research focuses on cross-modal data alignment and adaptive fusion by incorporating large foundation models, including large language models, to bridge semantic gaps across modalities. We address practical challenges such as missing modalities, noisy observations, and modality imbalance, with applications in medical data analysis and remote sensing. These efforts aim to enhance robustness, semantic consistency, and decision reliability in real-world multi-modal intelligence systems. >>Enter<<
Multi-modal data fusion aims to jointly model and integrate heterogeneous data from multiple modalities to enable comprehensive and reliable understanding of complex systems. Our research focuses on cross-modal data alignment and adaptive fusion by incorporating large foundation models, including large language models, to bridge semantic gaps across modalities. We address practical challenges such as missing modalities, noisy observations, and modality imbalance, with applications in medical data analysis and remote sensing. These efforts aim to enhance robustness, semantic consistency, and decision reliability in real-world multi-modal intelligence systems. >>Enter<<
Interpretable Neural Network(可解释神经网络)
 Brain-inspired large models aim to draw inspiration from the organizational and dynamical principles of biological neural systems to advance the interpretability, adaptability, and reliability of modern artificial intelligence. Synchronization is a powerful concept regulating a large variety of complex processes ranging from the metabolism in a cell to opinion formation in a group of individuals. Our research investigates neuronal-synchronization mechanisms as a foundational principle to develop interpretable neural networks, plastic neural architectures capable of continual adaptation, and reliable reasoning networks. By bridging neuroscience insights with large-scale learning models, we seek to build AI systems that exhibit structured representation, transparent decision processes, and robust inference under uncertainty. >>Enter<<
Brain-inspired large models aim to draw inspiration from the organizational and dynamical principles of biological neural systems to advance the interpretability, adaptability, and reliability of modern artificial intelligence. Synchronization is a powerful concept regulating a large variety of complex processes ranging from the metabolism in a cell to opinion formation in a group of individuals. Our research investigates neuronal-synchronization mechanisms as a foundational principle to develop interpretable neural networks, plastic neural architectures capable of continual adaptation, and reliable reasoning networks. By bridging neuroscience insights with large-scale learning models, we seek to build AI systems that exhibit structured representation, transparent decision processes, and robust inference under uncertainty. >>Enter<<
Spatial-Temporal Data Mining(时空数据挖掘)
 Spatial-temporal data mining aims to model and reason over dynamic data evolving across space and time in open and complex environments. Our research focuses on weak and novel target detection, open-set target recognition, and long-term tracking under low signal-to-noise conditions. By integrating multi-modal data fusion and graph-based learning for association and fusion tracking, we address challenges such as unknown target categories, intermittent observations, and cross-sensor uncertainty, enabling robust and adaptive spatial-temporal perception and inference. >>Enter<<
Spatial-temporal data mining aims to model and reason over dynamic data evolving across space and time in open and complex environments. Our research focuses on weak and novel target detection, open-set target recognition, and long-term tracking under low signal-to-noise conditions. By integrating multi-modal data fusion and graph-based learning for association and fusion tracking, we address challenges such as unknown target categories, intermittent observations, and cross-sensor uncertainty, enabling robust and adaptive spatial-temporal perception and inference. >>Enter<<
Interdisciplinary Research(交叉研究)
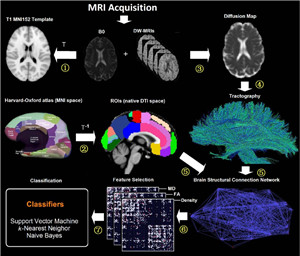 AI + Medicine: Mental diseases such as Alzheimer’s disease, schizophrenia and major depression, which now many people are paying extensive attention to, have become the most common diseases in the world. Research shows many mental diseases are associated with abnormality of brain networks, and fMRI, DTI and other neuroimaging techniques provide a way to acquire human brain’s structural connectome and functional connectome networks. Our goal is to find mental disease’s pathogenesis pattern or biomarker in brains by applying data mining and machine learning methods on brain networks, through which we can learn the internal pathogenesis of mental diseases, and it also helps doctor to diagnose mental diseases more objectively and accurately. >>Enter<<
AI + Medicine: Mental diseases such as Alzheimer’s disease, schizophrenia and major depression, which now many people are paying extensive attention to, have become the most common diseases in the world. Research shows many mental diseases are associated with abnormality of brain networks, and fMRI, DTI and other neuroimaging techniques provide a way to acquire human brain’s structural connectome and functional connectome networks. Our goal is to find mental disease’s pathogenesis pattern or biomarker in brains by applying data mining and machine learning methods on brain networks, through which we can learn the internal pathogenesis of mental diseases, and it also helps doctor to diagnose mental diseases more objectively and accurately. >>Enter<<
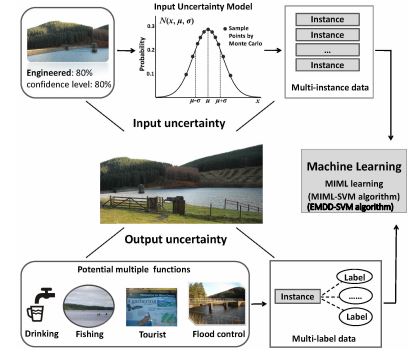 AI + Environment: AI + Environment focuses on applying advanced artificial intelligence techniques to environmental modeling and prediction, with a particular emphasis on runoff simulation and forecasting. Our research investigates data-stream-based runoff prediction under evolving hydrological conditions, fusion-based forecasting that integrates remote sensing imagery with in-situ ground station observations, and transfer learning methods for reliable prediction in data-scarce or missing regions. In addition, we explore high-quality environmental data generation to enhance model robustness and generalization, aiming to support accurate, adaptive, and scalable environmental intelligence in complex real-world scenarios. >>Enter<<
AI + Environment: AI + Environment focuses on applying advanced artificial intelligence techniques to environmental modeling and prediction, with a particular emphasis on runoff simulation and forecasting. Our research investigates data-stream-based runoff prediction under evolving hydrological conditions, fusion-based forecasting that integrates remote sensing imagery with in-situ ground station observations, and transfer learning methods for reliable prediction in data-scarce or missing regions. In addition, we explore high-quality environmental data generation to enhance model robustness and generalization, aiming to support accurate, adaptive, and scalable environmental intelligence in complex real-world scenarios. >>Enter<<